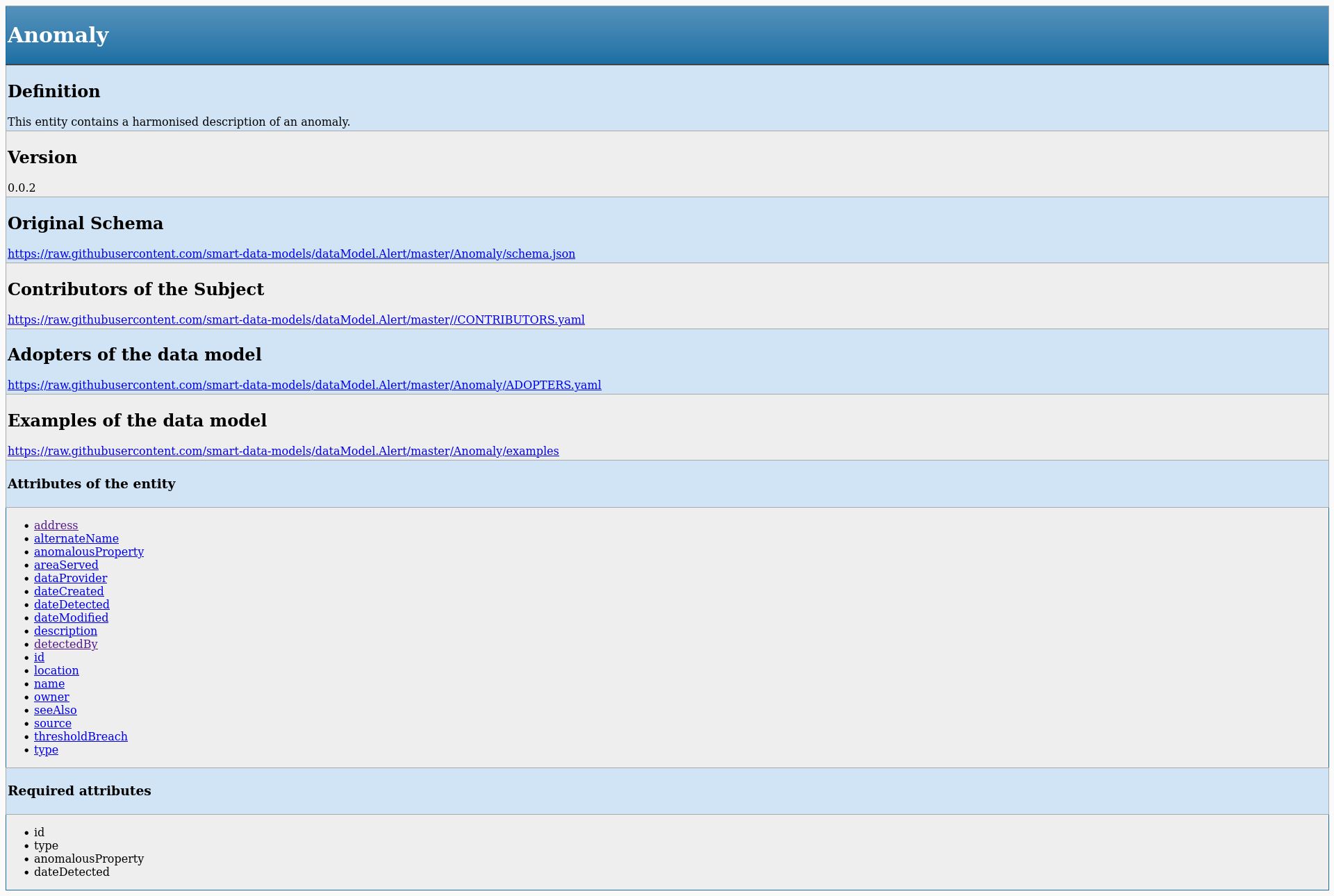
We are considering to officially provide an attestation of your contributions to SDM.
Before launching it officially we have created a drafted document for those contributors with a valid mail and name (there are people who do not want to disclose their contribution).
Accordingly, if you browse the database of contributors you will see a new column with the heading attestation and a download draft link.
By clicking on that link you can download the draft version of an attestation of your contribution.
We’ll be glad to receive your feedback on this initiative and the format and content of the attestation in the info@smartdatamodels.org address.
You can see an example below
attestation_alberto.abella@fiware.org_dataModel.Agrifood_2022


.jpg)