NEW VERSION!!
This post became obsolete, go for the new master sheet
This is a resource, especially for those who have limited knowledge of JSON schema.
If you want to create a basic version of a data model (not all JSON schema is implemented), you can use a copy of this spreadsheet as template. This spreadsheet is always available at https://bit.ly/schema_sheet short name.

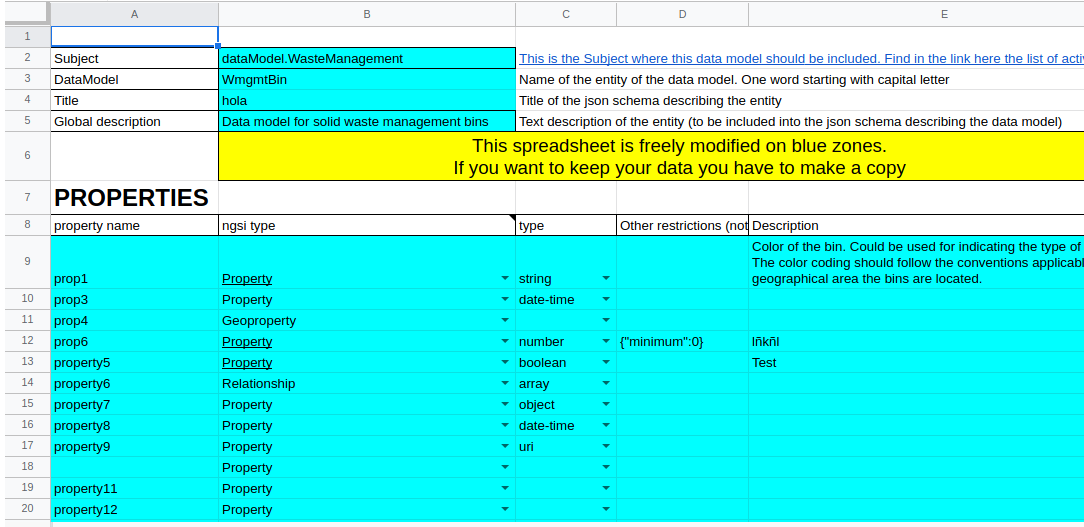
You need to fill the blue cells for these parameters:
- Subject: Official Subject where this data model should be allocated. (Check the official list)
- DataModel: Official data model name (Only one word i.e. WeatherForecast, no _).
- Title: use to be the name data model name with spaces. (i.e. Weather Forecast)
- Global Description: General text description of the data model. (2 lines is nice)
- Property name: Exactly this, the name of the property. Use camelCase. It would be good to check here whether this property already exists (you can copy and paste). Use those you need and leave one empty after those you filled. Properties below an empty property name are ignored.
- NGSI type: (Property, Relationship or Geoproperty)
- Data type: Type of data in the property. (array and object are not fully implemented)
- Other restrictions: If you are unfamiliar with JSON schema leave it empty.
- Description: Official description of the property.
Once you’ve got the schema, grab some examples (It is always good to review the contribution manual) and you can make a Pull Request on any of the subjects of any domain in Github. Or just use this form.
NOTE 1: The first option will be attended quicker than the second.
NOTE 2: Do not write out of the blue cells (it will be ignored). And do not add or remove cells. The converter script looks for these precise locations in blue.
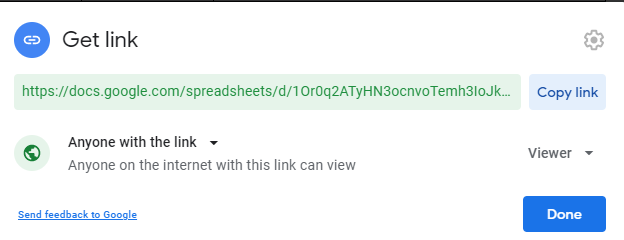
NOTE 3: Your spreadsheet has to be made public. (anyone with the link), otherwise, the script will not be able to retrieve your data.

Call:
Parameters: (Mandatories)
Output: A json schema based on the properties defined in the database. This is an alpha version so errors are not managed.