



In the directory utils of the umbrella repository data-models there is a new python script that checks if a schema is properly documented and if the payload is correctly located and validates against the schema.
No comments
In the directory utils of the umbrella repository data-models there is a new python script that checks if a schema is properly documented and if the payload is correctly located and validates against the schema.
In the front page, there is a new option that allows you top to directly create a copy of the template sheet for creating new data models.
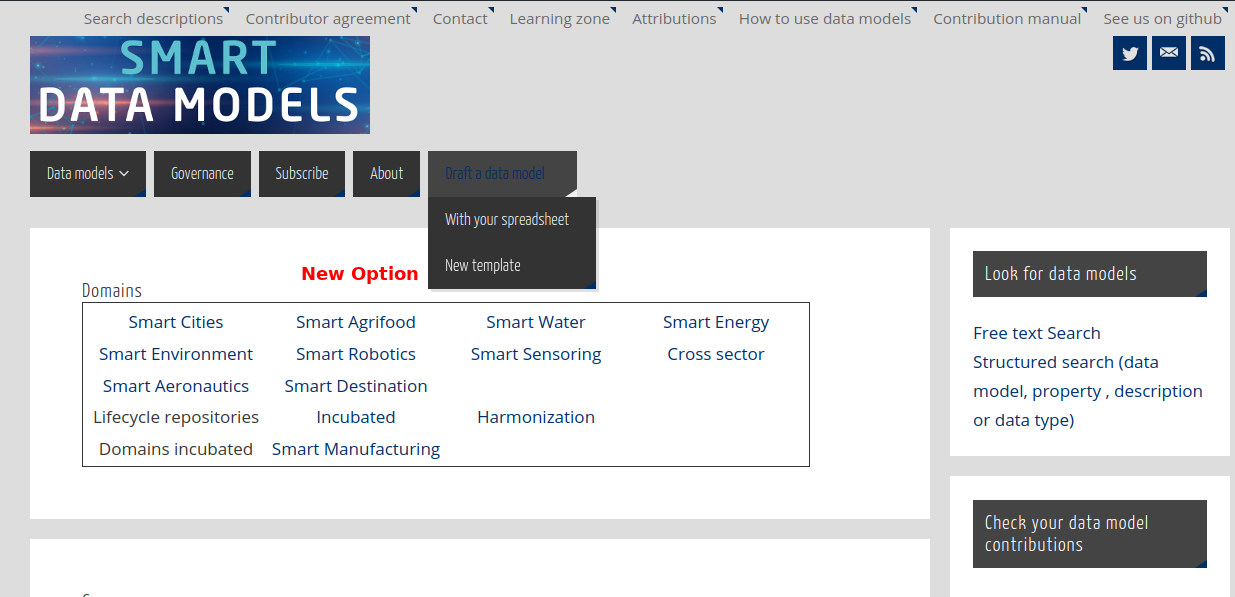
Remember that this spreadsheet is done for those unfamiliar with json schema (the official format for the smart data models) to allow them to create a new data model from their knowlege.
The use instructions are in the spreadsheet

Any doubt please let us know at info@smartdatamodels.org
The context.jsonld for smart data models has been updated to meet json ld requirements. Now they are implementing geojson requirements.
It affects the terms of bbox and coordinates. It could impact those elements having a geoproperty (most of the data models).
NEW VERSION!!
This post became obsolete, go for the new master sheet
This is a resource, especially for those who have limited knowledge of JSON schema.
If you want to create a basic version of a data model (not all JSON schema is implemented), you can use a copy of this spreadsheet as template. This spreadsheet is always available at https://bit.ly/schema_sheet short name.
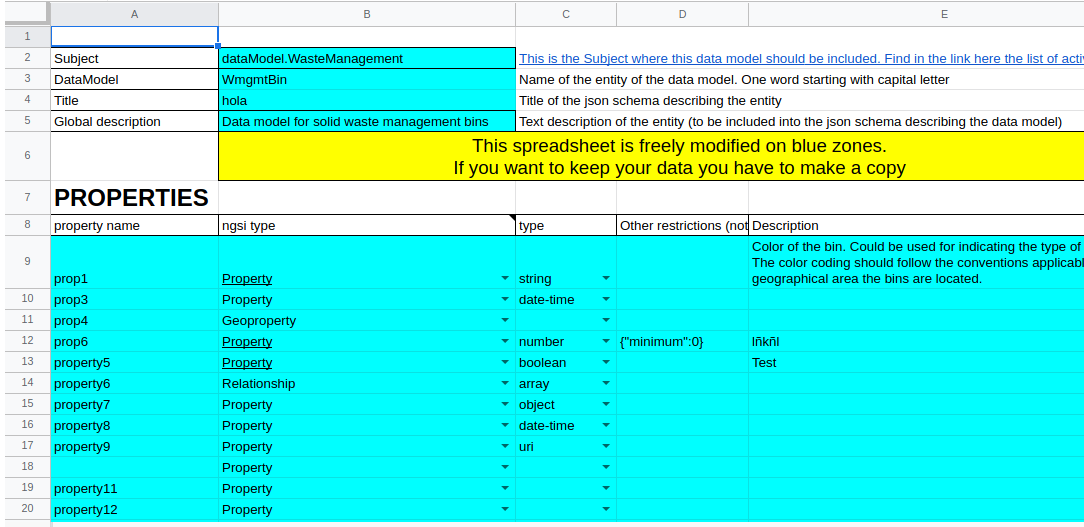
You need to fill the blue cells for these parameters:
Once you’ve got the schema, grab some examples (It is always good to review the contribution manual) and you can make a Pull Request on any of the subjects of any domain in Github. Or just use this form.
NOTE 1: The first option will be attended quicker than the second.
NOTE 2: Do not write out of the blue cells (it will be ignored). And do not add or remove cells. The converter script looks for these precise locations in blue.
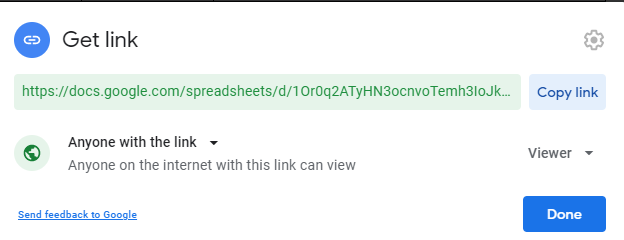
NOTE 3: Your spreadsheet has to be made public. (anyone with the link), otherwise, the script will not be able to retrieve your data.
Call:
Parameters: (Mandatories)
Output: A json schema based on the properties defined in the database. This is an alpha version so errors are not managed.
In case you are not an expert for creating a JSON schema (one of the elements of a data model)
On this page, you have a spreadsheet for helping with the first steps.
1.- Fill the spreadsheet with the names of the properties for your model
2.- fill the NGSI type (Property, Relationship or Geoproperty)
3.- In case of property, fill the data type (array and object types are currently not completely supported)
4.- Fill in the description
5.- Click the button, the page will reload
6.- voila! you have your json schema below the spreadsheet, just copy and paste into your favourite editor.
The python code for it is also made public in the utils directory in the data models repo.
The privacy of the data contained in a property has been under discussion for the documentation of any property.
Now there is a first version on how to implement it.
The contribution manual has been updated for this possibility. See the specific slide about it.
Privacy clause: Privacy:’[high/medium/low]
Describes if the property has any kind of information related with personal data. Current options:
Example:
“refUserDevice” :{
“description”: “Property. Model:’http://schema.org/Text’. Privacy:’low’. An object representing the current device used by the User.”.
It has been updated the format of the list of adopters of the data models (formerly were CURRENT-ADOPTERS.md markdown files), now in it is rename into ADOPTERS.yaml based on this yaml template which allows an automatic processing. (Further announcements could be included in a future).
Further instructions in the page Data Models Adopters how to located in the menu option Data models -> Data Models Adopters How to
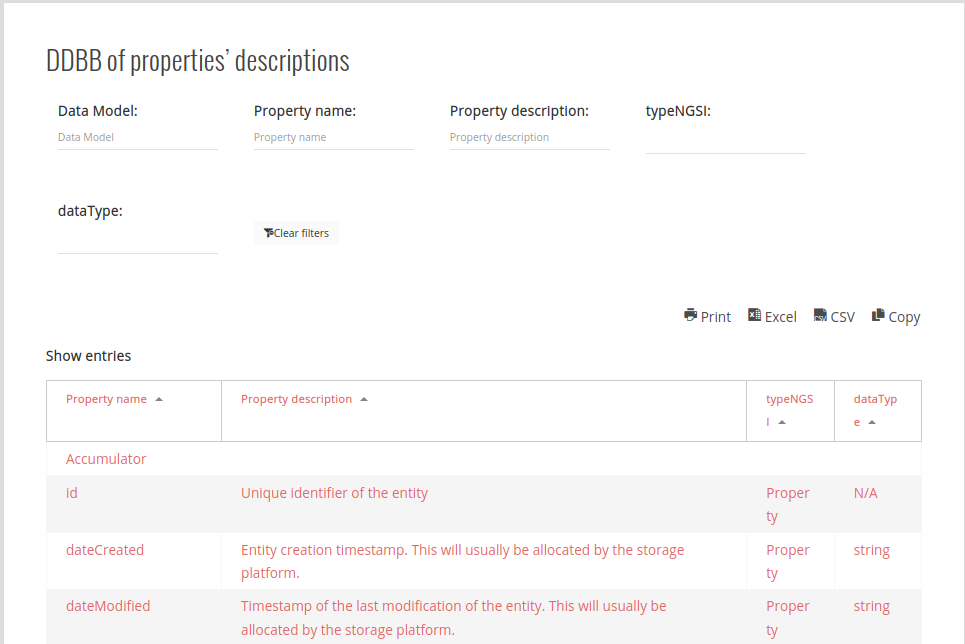
The database for the searching on data models, properties and their descriptions has been expanded to allow filtering also by :
Additionally, it has been updated containing more than 11.000 items
Accessible from the front page in this widget (Structured check)
You can export the results
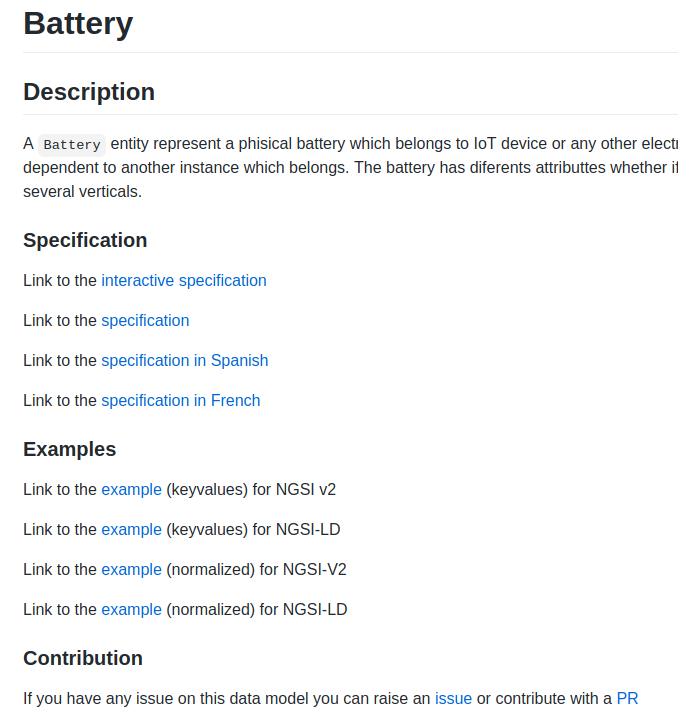
Now you can see the links to the specification in two languages, Spanish y French in the README.md of every data models. German and Japanese are in the queue.
See here an example
All the specifications (the text descriptions of the data model located in the /doc directory of each daat model) for the different domains and languages (currently French and Spanish besides English) have been updated to the new format. See an example in Spanish and French.
All of them are generated automatically from the json schema (which is the unique source of truth for the data model)
The contribution manual explains further details.
Raise an issue for any point you find in the new format.
