



The new data model, CurriculumVitae is located in the subject HumanResources, is derived from the original created by @David Bonilla at Manfred, it has been adapted to Smart Data Models.
- CurriculumVitae. An open Curriculum vitae format

The new data model, CurriculumVitae is located in the subject HumanResources, is derived from the original created by @David Bonilla at Manfred, it has been adapted to Smart Data Models.
FIWARE Foundation has joined the “Metaverse Standards Forum” The Metaverse Standards Forum is a non-profit, member-funded consortium of standards-related organizations, companies, and institutions that are cooperating to foster interoperability for an open and inclusive metaverse.
The Smart Data Models initiative is willing to contribute to those standards with all its data models to enable its use in the metaverse.
![]()
We provide a service to generate JSON schemas from the example payloads you provide. This service is designed to assist contributors who may have limited experience with JSON schemas but with actual examples. You can access the service through this link.
We are pleased to announce that we have made some updates to this service::
Please feel free to try it out and leave your comments on info@smartdatamodels.org.
We have introduced several new sections in the README.md for all the smart data models that we’ve published
These are:
Such as in the data model WeatherForecast:
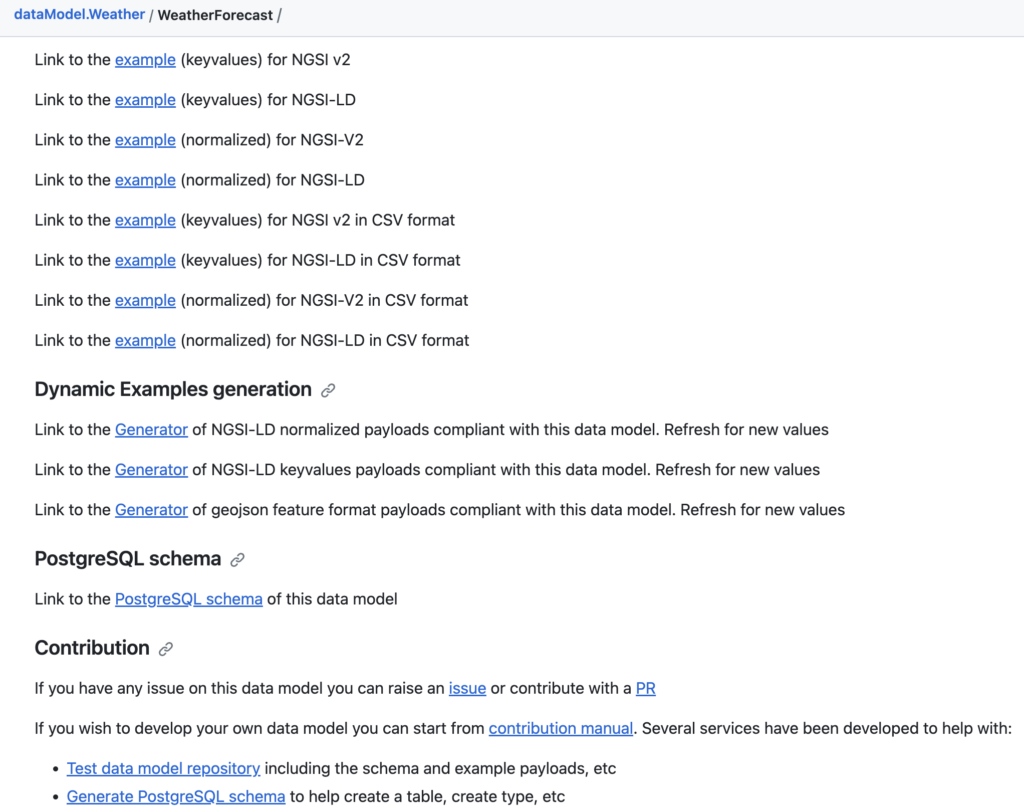
Hope you find it useful and feel free to make your comments on info@smartdatamodels.org.
There is a new version of the python package for pysmartdatamodels 0.6.1.
This python package includes all the data models and several functions to use them in your developments.
Changelog:
– Two updated functions
– Minor changes on providing links of repository, issues, updating on latest statistics, etc.

Get more details on the pypi page and feel free to try it out!
We are very close to launch a new service and we want to have your feedback on how to create this service.
So we made a Survey and you can help us by submitting your preference.
Thank you!
The contribution manual has minor updates frequently, but now we have created a brand new version
– Restructuring the contents
– Including explanation on how to use the test service for new data models
– Making more understandable the contribution workflow
– Guidelines for contributing
– The list of support channels, including the new on discord
– Move to the annex the slides for the automatic documents generated on the publication process
and helping to make more understandable to those users recently joining the Smart Data Models initiative.
As always the shortcut to reach it works: https://bit.ly/contribution_manual
But you can also find a direct link in these locations
Upper menu -> Contribution manual (7th option)
Main menu -> documentation -> Contribution manual (5th option in the drop down menu)
Feel free to make your comments on info@smartdatamodels.org or as comments in the manual.
The new version of the script for generating the specifications has been released in the directory utils of the umbrella repository data-models.
It allows the creation of the markdown specifications out of the json schema in multiple languages. If you have an account of DeepL API you can make the translations automatically.
Thanks to Konstantinos Gompakis from tuc.gr for this suggestion on others.
Hopefully you have unnoticed about several structural changes this weekend that has happen at SDM.
Now there are several additional information included.
— A unique id for every attribute of a version of a data model (i.e.
— The link to the parent’s attribute (whenever there is a parent) context link (i.e. https://smartdatamodels.org/address)
— The unique id of the parent attribute (whenever there is a parent) (i.e.
— The @context link of the attributes pointing to an existing web page with some details about the attribute (i.e. https://smartdatamodels.org/postOfficeBoxNumber)
Now the second level of attributes is available in the specification document for all the languages (i.e. https://github.com/smart-data-models/dataModel.User/blob/master/Activity/doc/spec.md)
Now the second and subsequent levels of the attributes have URI entries in the @context included in the file context.jsonld file in every subject (i.e. https://github.com/smart-data-models/dataModel.Environment/blob/master/context.jsonld)
The URI of the data models points to a existing web page (i.e. https://smartdatamodels.org/dataModel.Environment/ambientNoiseTSA)
Besides this we welcome a new member of the SDM team, Rihab Feki.

questions/suggestions to info@smartdatamodels.org
There is a new version of the python package for pysmartdatamodels 0.6.0.
This python package includes all the data models and several functions to use them in your developments.
Changelog:
– Four new functions
– Acknowledgement session has been added into the README.

Get more details on the pypi page and feel free to try it out!
