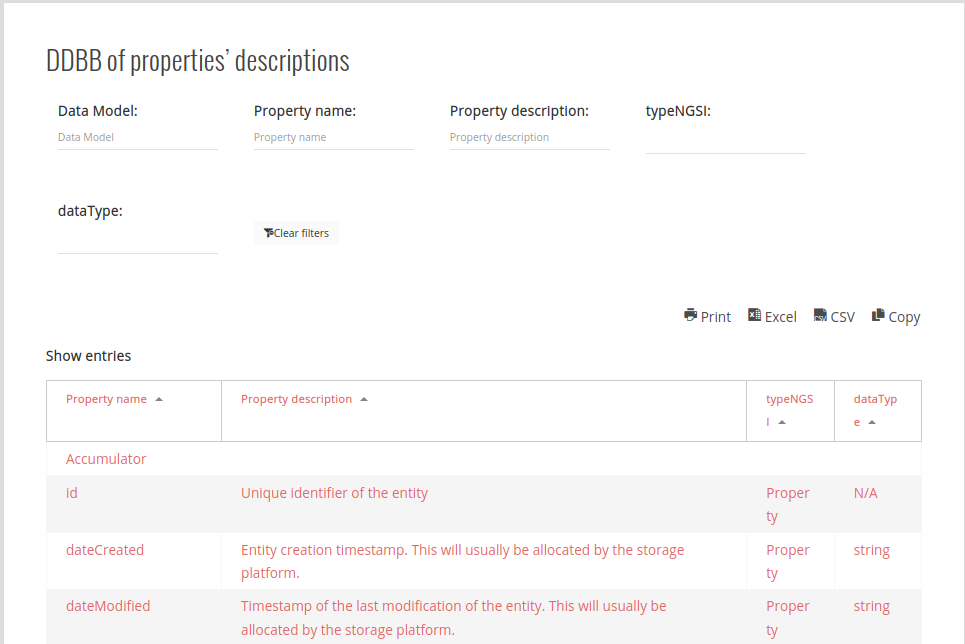
The database for the searching on data models, properties and their descriptions has been expanded to allow filtering also by :
- NGSI type (one of Property, Relationship or Geoproperty)
- data type (string, number, boolean, array, object, etc)
Additionally, it has been updated containing more than 11.000 items
Accessible from the front page in this widget (Structured check)
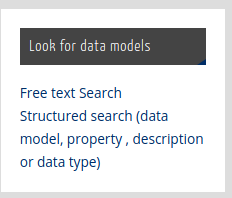
You can export the results