In the context.jsonld of every subject there are long IRI for every first-level attribute and for the names of the entities. See this example.
formerly the link of the attributes took you to an existing web page while the links of the entities take you nowhere. Strictly there is not need to take anywhere, however, it would be useful to create such pages with basic information. Now there are also links to the entities’ pages, where a new page is being created. See this example.
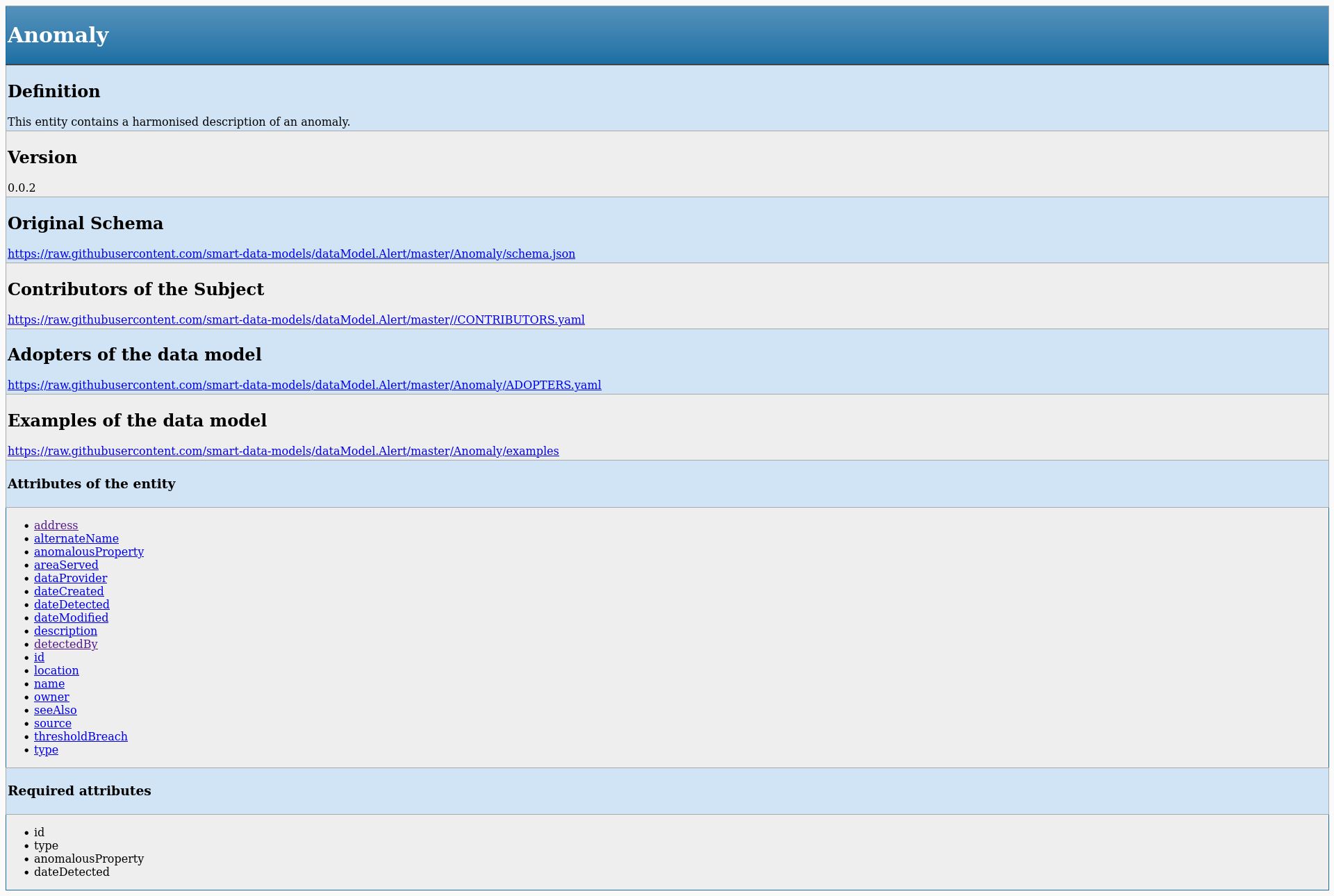
Now all of them have their own page with these sections
0.- Make a local copy in your google account and grant permission the first time you use it (it warns you that it is not validated by google, true, but anyhow go to advance and grant the permissions
1.- Include your example in json key values
2.- Include the name of the data model, its title, the subject, and the description together with your email
3.,- Describe the attributes, their NGSI type, their data type, and the written description.
We have noticed an error in the description of the attribute location in the file common-schema.json, a file that is embedded in most of the data models. It does not affect the data types (so the validation of the schemas is not affected) but it affects the qualification of the NGSI type that it is not properly identified,
GeoProperty is written with capital middle P.
The file has been updated and soon it will be launched an update of all the data models affected.