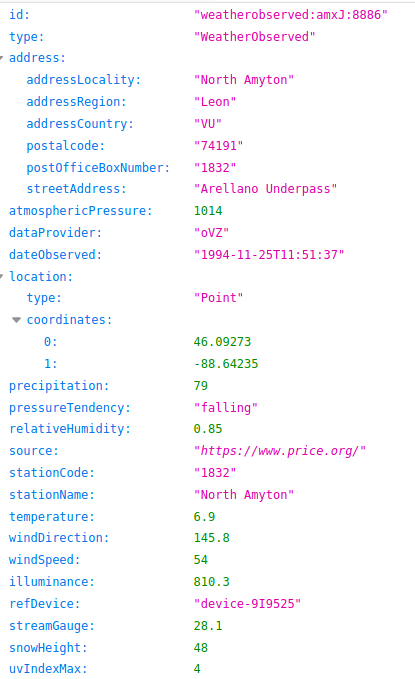
We’ve submitted into the utils directory a short script for installing and running an instance of NGSI v2 and to create your first entity and to list it. It is not a complete guide which is available at FIWARE mains page in this link.
# 1.- if your are coming from a clean installation
sudo docker pull mongo:3.6
sudo docker pull fiware/orion
sudo docker network create fiware_default
sudo docker run -d –name=mongo-db –network=fiware_default –expose=27017 mongo:3.6 –bind_ip_all –smallfiles
sudo docker run -d –name fiware-orion -h orion –network=fiware_default -p 1026:1026 fiware/orion -dbhost mongo-db
# 2.- In case you already had a installation it is better to run these instructions
docker stop fiware-orion
docker rm fiware-orion
docker stop mongo-db
docker rm mongo-db
docker network rm fiware_default
# 3.- Check that your installation is up and running
curl -X GET ‘http://localhost:1026/version’
# 4.- Create your first entity
curl -iX POST ‘http://localhost:1026/v2/entities’ -H ‘Content-Type: application/json’ -d ‘
{
“id”: “urn:ngsi-ld:PhotovoltaicDevice:PhotovoltaicDevice:MNCA-PV-T2-R-012”,
“type”: “PhotovoltaicDevice”,
“name”: {
“type”: “Property”,
“value”: “DEVICE-PV-T2-R-012”
},
“alternateName”: {
“type”: “Property”,
“value”: “AirPort – global Observation”
},
“description”: {
“type”: “Property”,
“value”: “Photo-voltaic Device description”
},
“location”: {
“type”: “GeoProperty”,
“value”: {
“type”: “Point”,
“coordinates “: [43.664810, 7.196545]
}
},
“address”: {
“type”: “Property”,
“value”: {
“addressCountry”: “FR”,
“addressLocality”: “Nice”,
“streetAddress”: “Airport – Terminal 2 – Roof 2 – Local 12”
}
},
“areaServed”: {
“type”: “Property”,
“value”: “Nice Aeroport”
},
“refDevice”: {
“type”: “Relationship”,
“value”: “urn:ngsi-ld:Device:PV-T2-R-012”
},
“brandname”: {
“type”: “Property”,
“value”: “Canadian Solar”
},
“modelName”: {
“type”: “Property”,
“value”: “CS6P-270P”
},
“manufacturerName”: {
“type”: “Property”,
“value”: “Canadian Solar EMEA GmbH,”
},
“serialNumber”: {
“type”: “Property”,
“value”: [“CSPV270P-SN1804L6J34Z8742H”,
“CSPV270P-SN1804L6J34Z8743H”,
“CSPV270P-SN1804L6J34Z8744H”,
“CSPV270P-SN1804L6J34Z8745H”,
“CSPV270P-SN1804L6J34Z8746H”
]
},
“application”: {
“type”: “Property”,
“value”: “electric”
},
“cellType”: {
“type”: “Property”,
“value”: “polycrystalline”
},
“instalationMode”: {
“type”: “Property”,
“value”: “roofing”
},
“instalationCondition”: {
“type”: “Property”,
“value”: [“extremeHeat”, “extremeCold”, “extremeClimate”, “desert”]
},
“possibilityOfUsed”: {
“type”: “Property”,
“value”: “stationary”
},
“integrationMode”: {
“type”: “Property”,
“value”: “IAB”
},
“documentation”: {
“type”: “Property”,
“value”: “https://www.myDevicePV.Cn”
},
“owner”: {
“type”: “Property”,
“value”: [“Airport-Division Maintenance”]
},
“cellDimension”: {
“type”: “Property”,
“value”: {
“length”: 16.0,
“width”: 9.0,
“thickness”: 2.3
}
},
“moduleNbCells”: {
“type”: “Property”,
“value”: 60
},
“moduleDimension”: {
“type”: “Property”,
“value”: {
“length”: 1600,
“width”: 975,
“thickness”: 3.75
}
},
“panelNbModules”: {
“type”: “Property”,
“value”: 1
},
“panelDimension”: {
“type”: “Property”,
“value”: {
“length”: 1638,
“width”: 982,
“thickness”: 40
}
},
“panelWeight”: {
“type”: “Property”,
“value”: 18
},
“arealWeight”: {
“type”: “Property”,
“value”: 32
},
“maxPressureLoad”: {
“type”: “Property”,
“value”: {
“hail”: 2500,
“snow”: 5400,
“wind”: 2400
}
},
“NominalPower”: {
“type”: “Property”,
“value”: 270
},
“MaximumSystemVoltage”: {
“type”: “Property”,
“value”: 1000
},
“applicationClass”: {
“type”: “Property”,
“value”: “A”
},
“fireClass”: {
“type”: “Property”,
“value”: “C”
},
“pTCClass”: {
“type”: “Property”,
“value”: 92.1
},
“nTCClass”: {
“type”: “Property”,
“value”: 88.3
},
“protectionIP”: {
“type”: “Property”,
“value”: “IP67”
},
“moduleSTC”: {
“type”: “Property”,
“value”: {
“Pmax”: 270,
“Umpp”: 30.8,
“Impp”: 8.75,
“Uoc”: 37.9,
“Isc”: 9.32
}
},
“moduleNOCT”: {
“type”: “Property”,
“value”: {
“Pmax”: 196,
“Umpp”: 28.1,
“Impp”: 6.97,
“Uoc”: 34.8,
“Isc”: 7.55
}
},
“moduleYieldRate”: {
“type”: “Property”,
“value”: 16.79
},
“panelOperatingTemperature”: {
“type”: “Property”,
“value”: {
“min”: -40,
“max”: 85
}
},
“cellOperatingTemperature”: {
“type”: “Property”,
“value”: {
“min”: 45,
“max”: 2
}
},
“temperatureCoefficient”: {
“type”: “Property”,
“value”: {
“Pmax”: -0.41,
“Uoc”: -0.31,
“Isc”: 0.053
}
},
“performanceLowIrradiance”: {
“type”: “Property”,
“value”: 96.5
},
“panelLifetime”: {
“type”: “Property”,
“value”: 30
},
“panelYieldCurve”: {
“type”: “Property”,
“value”: [“95.0”, “92.5”, “90.0”, “87.5”, “85.0”, “80.0”]
},
“panelYieldRate”: {
“type”: “Property”,
“value”: 0.5
},
“panelTiltReference”: {
“type”: “Property”,
“value”: {
“min”: 28,
“max”: 37
}
}
}
‘
# 5.- List the entity you have created
curl -G -X GET ‘http://localhost:1026/v2/entities’ -d ‘options=keyValues’