The Smart Data Models now has a Candidates repository — a low-friction entry point where any existing standard, ontology or open dataset can be translated into the SDM shape (JSON Schema + NGSI-LD context + examples) before anyone commits to the full contribution process. The first entry, translated from the EDINT Infrastructure Ontology, is live today — and it needs your help to move forward.
What is the Candidates repository?
Until now, turning an external standard into a Smart Data Model meant going almost straight to the Incubated repository, where a contributor actively develops the model to the point of passing our full validation suite and preparing it for official publication. That’s the right process once someone is committed to doing the work — but it leaves no room for a lighter step: “here is a standard that looks like it maps well onto NGSI-LD — does anyone want to develop this further?”
The Candidates repository fills that gap. It maps existing standards — ontologies, open data schemas, sector vocabularies — into the SDM format (JSON Schema, JSON-LD context, key-value and NGSI-LD normalized examples) as a starting point, organized standard-first:
standards/<standard-slug>/
standard-metadata.yaml
models/<EntityName>/
schema.json
context.jsonld
examples/
example.json
example-normalized.jsonld
A candidate is not a finished data model. It’s a proposal: a structurally valid, plausible translation that any user of Smart Data Models can pick up, test against real payloads, comment on, correct, or use as the basis for a full contribution to Incubated.
The first example: the EDINT Infrastructure Ontology
The first entry, edint-infraestructura, translates the EDINT Infrastructure Ontology — a formal OWL vocabulary developed under the EU-funded EDINT (Espacio de Datos para las Infraestructuras Urbanas Inteligentes) project for describing a municipality’s public and private facilities: educational, cultural, social and sports centers, health centers, on-street and off-street parking, and shared-bicycle stations, together with the sensors, observations, management roles and organizations involved in operating them.
Eleven candidate models were generated: Facility, Parking, BikeSharingStation, ObservationPoint, AccessSensor, CountingSensor, AccessObservation, CountingObservation, Violation, ManagementRole and Organization. Every schema is valid JSON Schema (Draft 2020-12) and every example validates against its own schema — but that’s where “finished” stops. In the spirit of being upfront about what a Candidate actually is, here’s exactly where this one stands:
- Real examples exist for only one of the eleven models.
Facilityis grounded in a real record from the source ontology’s own example data (a municipal day-care center in Madrid). The other ten — the sensors, observations, violations, roles — have plausible but synthetic example payloads, because the source ontology itself doesn’t ship real instance data for them. This is the single most useful thing the community could contribute right now: real payloads from an actual access-control sensor, a real counting observation, a real management-role record. - Two models likely duplicate existing official subjects.
ParkingandOrganizationare thin, attribute-free specializations in the source ontology and may well overlap with the existing officialdataModel.ParkinganddataModel.Organization. This needs a real review before either goes any further. - The source ontology is licensed CC-BY-SA-4.0 (ShareAlike), while SDM contributions are conventionally CC-BY-4.0. This hasn’t been resolved and is flagged directly in the candidate’s
standard-metadata.yamlfor whoever picks this up next. - Geolocation needs a second look. The source ontology’s geometry is expressed in a projected coordinate system (not WGS84), so the example coordinates here are illustrative Madrid locations, not verified reprojections of the original data.
None of this makes the candidate useless — quite the opposite. It’s exactly the kind of concrete, checkable list that turns “someone should look into this standard” into a set of small, tractable tasks anyone can pick up.
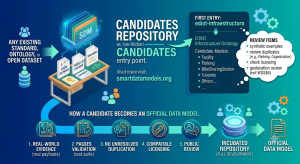
How a Candidate could become an official data model
There is no formal graduation process yet, and we’d rather propose one in the open than invent it quietly. Here’s a first draft, and we’re actively looking for feedback on it:
- Real-world evidence. At least one model in the candidate has real, non-synthetic example payloads from an actual system or dataset using it.
- Passes validation. The candidate’s schemas and examples pass the standard SDM test suite with zero blocking failures (the same 12 checks used for Incubated contributions).
- No unresolved duplication. Any overlap with an existing official model has been explicitly checked and either resolved (extend the existing model instead) or justified (the candidate covers something genuinely different).
- Compatible licensing. The source material’s license allows redistribution under the terms Smart Data Models publishes under.
- A short public review. A brief comment period on the candidate’s pull request or a linked issue, open to anyone in the community.
Once a candidate clears these, it moves into the normal Incubated workflow for full development ahead of official publication.
How to get involved
- Browse the repository: github.com/smart-data-models/Candidates
- Search all candidates: smart-data-models.github.io/Candidates — a searchable, always up to date index of every candidate standard and model
- Contribute a real example for any of the eleven EDINT models above — open a pull request against
standards/edint-infraestructura/, or an issue if you’re not sure how. - Propose a new candidate: if you know a standard, ontology or open dataset that should have an SDM mapping, open an issue describing it, or submit the translated
standards/<slug>/folder directly. - Give feedback on the promotion criteria above — they’re a first draft, not a final decision.
Find all published Smart Data Models at smartdatamodels.org/ search menu, and everything currently in development in the Incubated repository.